
Enterprise applications increasingly rely on large amounts of data, that needs be distributed, processed, and stored. Open source and commercial supported software stacks are available to implement a data platform, that can offer common data management services, accelerating the development and deployment of data hungry business applications, VMware has made it simple for cloud providers to offer, deploy and manage using Data Platform Blueprint.
Understand Validated Blueprint and Requirement for Data Platform
You can find validated blueprint designs in the Bitnami Application Catalog and VMware Marketplace, including blueprints for building containerized data platforms with Kafka, Apache Spark, Solr, and Elasticsearch.

These engineered and tested data platform blueprints are implemented via Helm charts. They capture security and resource settings, affinity placement parameters, and observability endpoint configurations for data software runtimes. Using the Helm CLI or KubeApps tool, Helm charts enable the single-step, production-ready deployment of a data platform in a Kubernetes cluster, covering automated installation and the configuration of multiple containerized data software runtimes.
Each data platform blueprint comes with Kubernetes cluster node and resource configuration guidelines to ensure the optimized sizing and utilization of underlying Kubernetes cluster compute, memory, and storage resources. For example, README.md covers the Kubernetes deployment guidelines for the Kafka, Apache, Spark, and Solr blueprint.
This Blueprint enables the fully automated Kubernetes deployment of such multi-stack data platform, covering the following software components:
- Apache Kafka – Data distribution bus with buffering capabilities
- Apache Spark – In-memory data analytics
- Solr – Data persistence and search
- Data Platform Signature State Controller – Kubernetes controller that emits data platform health and state metrics in Prometheus format.
These containerized stateful software stacks are deployed in multi-node cluster configurations, which is defined by the Helm chart blueprint for this data platform deployment, covering:
- Pod placement rules – Affinity rules to ensure placement diversity to prevent single point of failures and optimize load distribution
- Pod resource sizing rules – Optimized Pod and JVM sizing settings for optimal performance and efficient resource usage
- Default settings to ensure Pod access security
Cloud Director Provider Configuration
Install and Configure VMware Cloud Director App Launchpad
App Launchpad is a VMware Cloud Director service extension which service providers can use to create and publish catalogs of deployment-ready applications. Tenant users can then deploy the applications with a single click, for App Launch Pad Install and Configure see Here , once App Launchpad is installed, configure it with Bitnami helm repository as below:
- Log in to the VMware Cloud Director service provider admin portal.
- From the main menu (), select App Launchpad
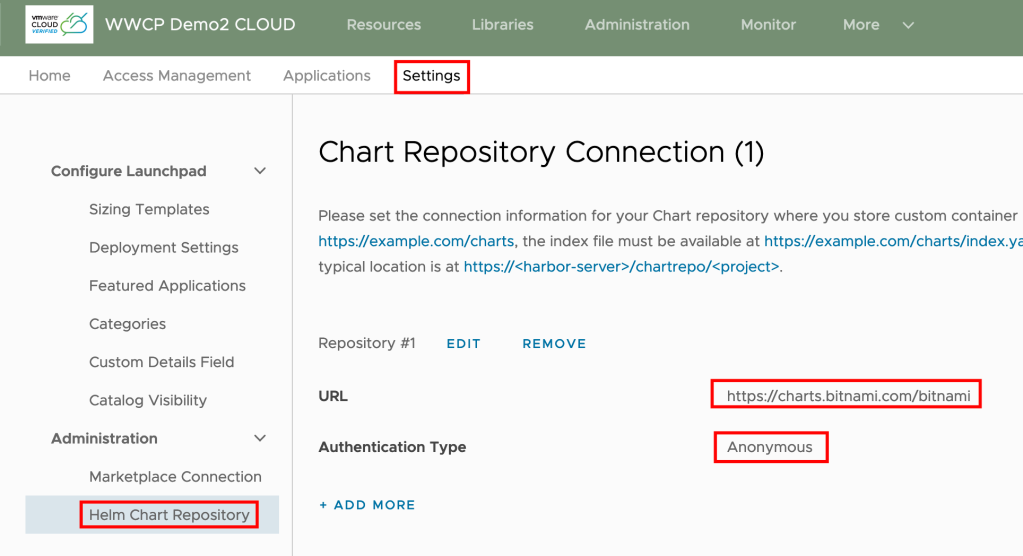
- On the Settings tab, click on Helm Chart Repository
- Click Add.
- Add the required repository details.
- Enter the URL of the repository, for Data Platform blueprint use – https://charts.bitnami.com/bitnami
- Select the authentication type as Anonymous
- Click Save.
Add DataPlatform Blueprint from Helm Chart Repository
- Log in to the VMware Cloud Director service provider admin portal.
- From the main menu (), select App Launchpad.
- On the Applications tab, click Add New.
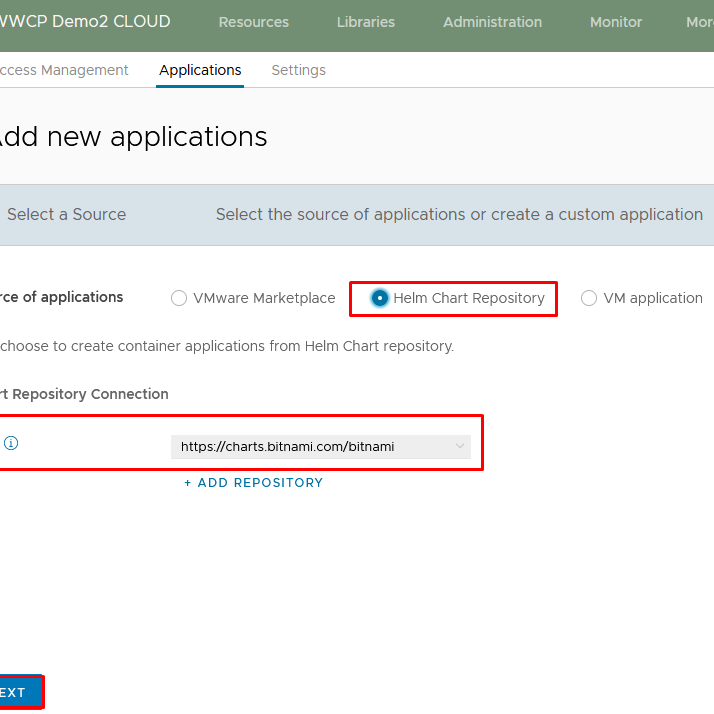
- Select Chart Repository as the application source.
- Select the chart repository from which you want to import applications and click Next.
- Select the application and application version that you want to add and click Next.You can add multiple applications at once.
- Select an existing VMware Cloud Director catalog to which you add the application or create one, and click Next.
- Review the applications details and click Add.
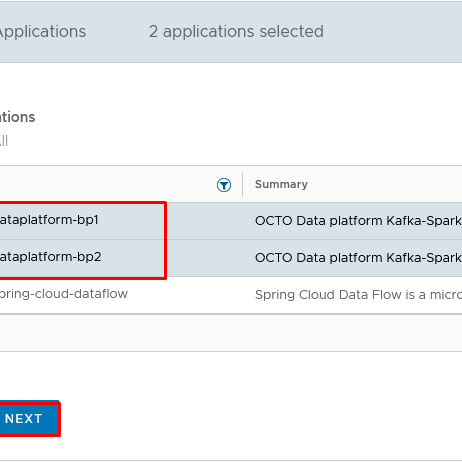

Tenant Self-Service Deployment
Once Provider has published Data Platfrom blue prints to tenants, tenants can deploy those on Tanzu Kubernetes Cluster in self service way. so before deploying tenant must need to:
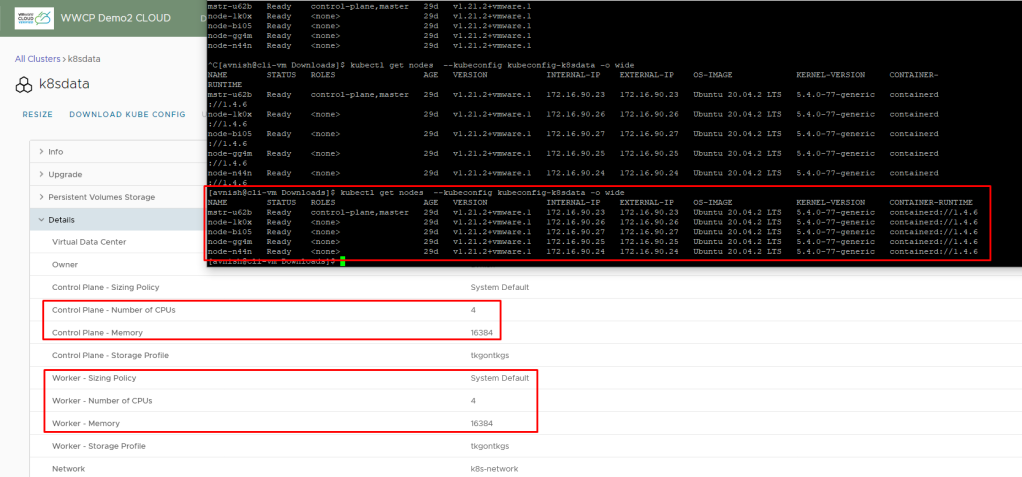
- Create Tanzu Kubernetes Cluster with enough CPU and Memory to master and worker nodes, for this blog i created a four node worker cluster with 4 vCPU and 16 GB Memory.
Below are the minimum Kubernetes Cluster requirements for “Small” size data platform:
| Data Platform Size | Kubernetes Cluster Size | Usage |
|---|---|---|
| Small | 1 Master Node (2 CPU, 4Gi Memory) 3 Worker Nodes (4 CPU, 32Gi Memory) | Data and application evaluation, development, and functional testing |
- Create Default Storage Class – Once Tanzu Kubernetes Cluster created, create an default stoage class for Tanzu Kubernetes cluster using below sample yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true" <ensure true>
name: vcd-disk-dev
provisioner: named-disk.csi.cloud-director.vmware.com
reclaimPolicy: Delete
parameters:
storageProfile: "Tanzu01" <your org VDC stroage policy>
filesystem: "ext4"
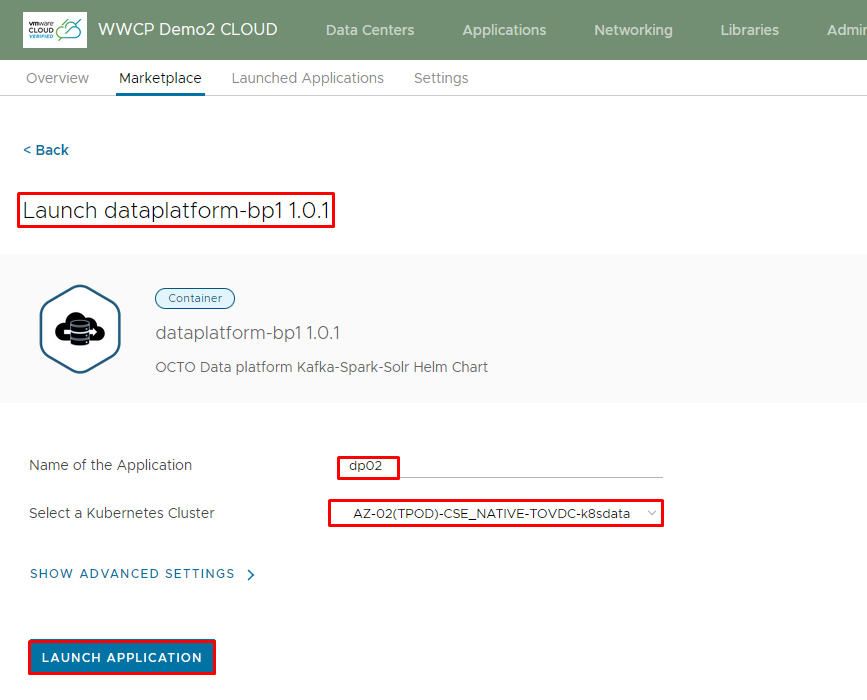
- Tenant Deploys Data Platform BluePrint – Now Tenant goes ahead in Cloud Director App launchpad and deploys Data Platform Blueprint using their choice of settings or with default settings
- Select DataPlatform Blue Print and click on Deploy
- Enter Application Name
- Select Tanzu Kubernetes Cluster on which tenant want to install data platform
- Click on “Launch Application”
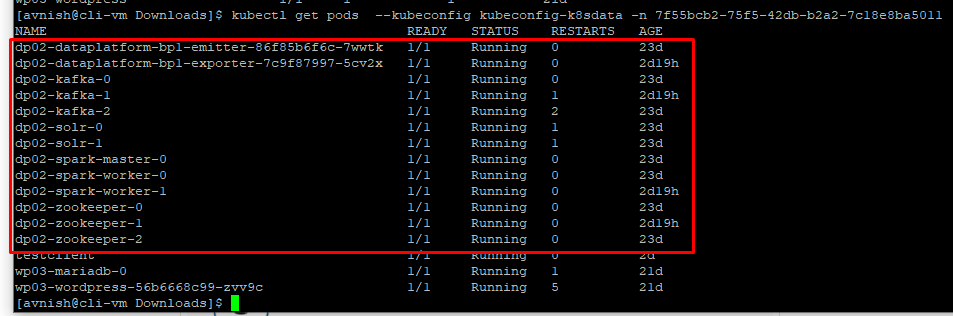
- This blue print bootstraps Data Platform Blueprint-1 deployment on a Kubernetes cluster using the Helm package manager.Once the chart is installed, the deployed data platform cluster comprises of:
- Zookeeper with 3 nodes to be used for both Kafka and Solr
- Kafka with 3 nodes using the zookeeper deployed above
- Solr with 2 nodes using the zookeeper deployed above
- Spark with 1 Master and 2 worker nodes
- Data Platform Metrics emitter and Prometheus exporter
this process will also create required persistent volumes for the application, you can view the persistent volumes inside cloud director console, by going in to Tanzu Kubernetes cluster
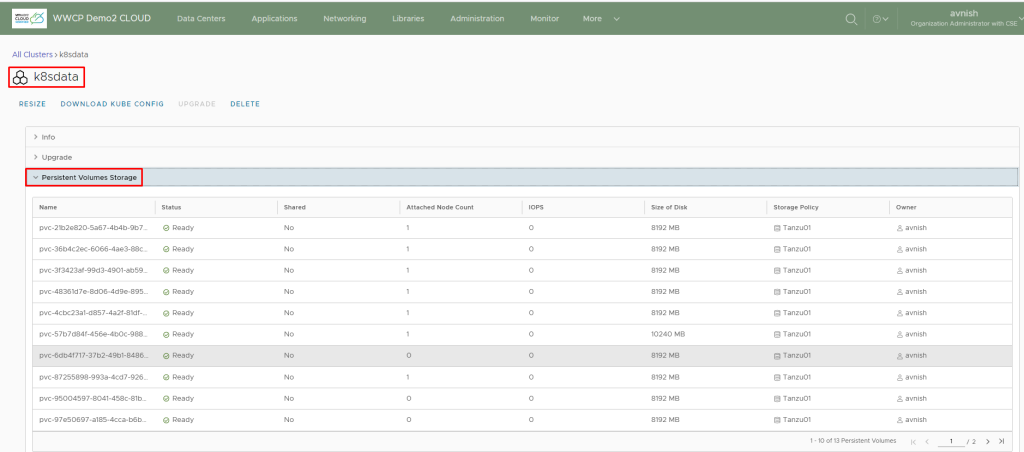
or by going in to Organization VDC and click on “Named Disks”
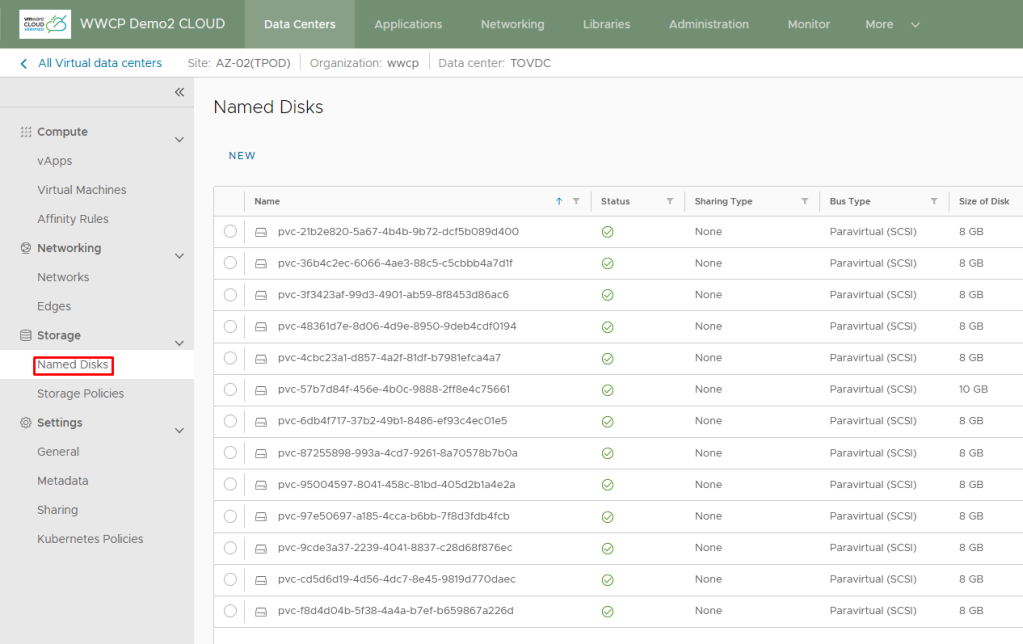
The entire process takes some time, once done tenant should see all the pods are up and running, all the required volumes are created and attached and all the required services are exposed.
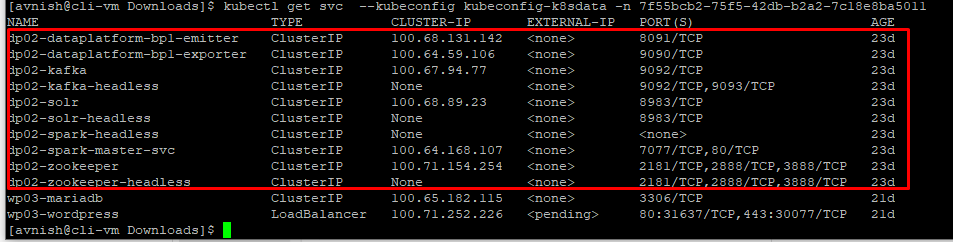
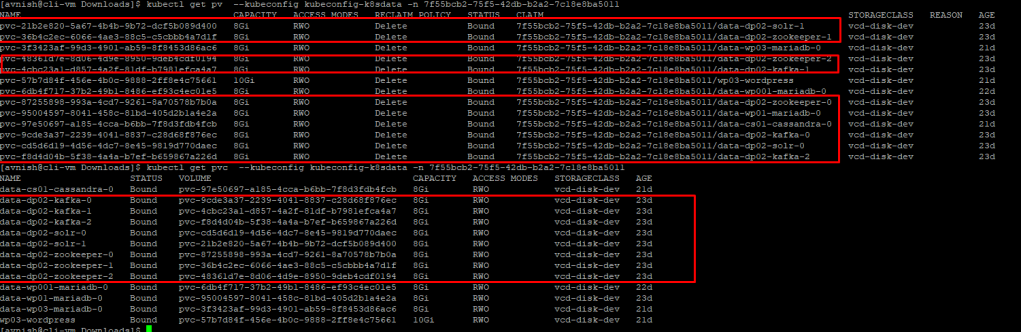
Testing the Kafka Cluster
(I am not Kafka expert took testing guidance from Internet, specially Platform9 website)
We are going to deploy a test client that will execute scripts against the Kafka cluster.Create and apply the following deployment:
$ vi testclient.yaml
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: kafka
spec:
containers:
- name: kafka
image: solsson/kafka:0.11.0.0
command:
- sh
- -c
- "exec tail -f /dev/null"
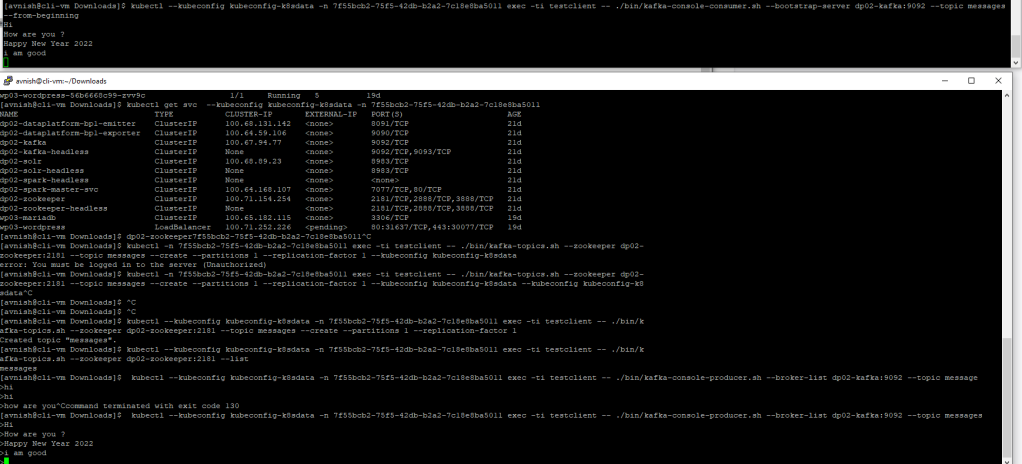
$ kubectl apply -f testclient.yamlnow lets use this “testclient" container, we will create the first topic, which we are going to use to post messages:
$ kubectl --kubeconfig kubeconfig-k8sdata -n 7f55bcb2-75f5-42db-b2a2-7c18e8ba5011 exec -ti testclient -- ./bin/kafka-topics.sh --zookeeper dp02-zookeeper:2181 --topic messages --create --partitions 1 --replication-factor 1
make sure you use the correct hostname for zookeeper cluster and the topic configuration. now lets verify that topic exists by using below command:
$ kubectl --kubeconfig kubeconfig-k8sdata -n 7f55bcb2-75f5-42db-b2a2-7c18e8ba5011 exec -ti testclient -- ./bin/kafka-topics.sh --zookeeper dp02-zookeeper:2181 --list

Now we can create one consumer and one producer instance so that we can send and consume messages. Open two putty shells and on first shell create consumer:
$ kubectl --kubeconfig kubeconfig-k8sdata -n 7f55bcb2-75f5-42db-b2a2-7c18e8ba5011 exec -ti testclient -- ./bin/kafka-console-consumer.sh --bootstrap-server dp02-kafka:9092 --topic messages --from-beginningon second shell, create producer and start sending messages:
$kubectl --kubeconfig kubeconfig-k8sdata -n 7f55bcb2-75f5-42db-b2a2-7c18e8ba5011 exec -ti testclient -- ./bin/kafka-console-producer.sh --broker-list dp02-kafka:9092 --topic messages
>Hi
>How are you ?
On consumer shell, you should see these messages getting populated using data streaming platform.
Cloud Director with Container Service Extention along with App Launchpad offers easist way for providers to offer many monitizable services in multi-tenant environment and easiest way to deploy and consume these services for tenants. so providers what are you waiting for ?

{kind=link}